

GPORCA 概述
GPORCA 是在 Postgres 查询优化器基础上构建的增强版优化器,增强了查询规划和优化能力。它具有良好的扩展性,特别是在多核架构下能实现更高效的优化效果。Apache Cloudberry 默认在支持的场景下使用 GPORCA 生成查询执行计划。
GPORCA 在以下方面显著增强了 Apache Cloudberry 的查询性能:
- 分区表查询
- 含公用表表达式(CTE)的查询
- 含子查询的查询
在 Apache Cloudberry 中,GPORCA 与基于 Postgres 的优化器同时存在。默认情况下,系统优先尝试使用 GPORCA。当 GPORCA 不支持某些查询时,系统会自动回退使用 Postgres 优化器。
下图展示了 GPORCA 在整体查询规划架构中的位置:
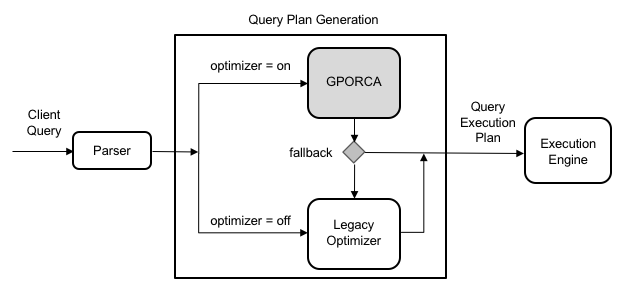
需要注意的是,所有用于配置 Postgres 优化器行为的服务器参数在 GPORCA 模式下均被忽略。仅当系统回退使用 Postgres 优化器时,这些参数才会影响查询计划的生成。
启用或禁用 GPORCA
可以通过服务器配置参数 optimizer 启用或禁用 GPORCA。
虽然系统默认启用 GPORCA,但你也可以在系统、数据库、会话或查询级别灵活配置 optimizer 参数,控制是否使用 GPORCA。
optimizer参数用于启用或禁用 GPORCA。optimizer_control参数用于控制是否允许修改optimizer的值。当optimizer_control为off时,尝试更改optimizer参数会报错。只有将其设置为on,才允许修改optimizer参数。
为系统启用 GPORCA
通过设置服务器参数 optimizer,可以在整个系统范围内启用 GPORCA。
-
使用 Apache Cloudberry 管理员用户
gpadmin登录到主节点。 -
通过以下
gpconfig命令设置参数值为on:gpconfig -c optimizer -v on --coordinatoronly -
使用以下命令重载配置,无需重启系统即可应用更改:
gpstop -u
为数据库启用 GPORCA
可以使用 ALTER DATABASE 命令为指定数据库启用 GPORCA。如下示例为数据库 test_db 启用 GPORCA:
ALTER DATABASE test_db SET optimizer = on;
为会话或查询启用 GPORCA
使用 SET 命令可以在当前会话中启用 GPORCA。例如,在通过 psql 连接 Apache Cloudberry 后执行以下命令:
SET optimizer = on;
若需仅对某条查询启用 GPORCA,可在执行该查询前运行上述 SET 命令。
确定使用的查询优化器
当 GPORCA 处于启用状态(默认配置)时,你可以通过以下方式确认 Apache Cloudberry 实际使用的是 GPORCA 还是回退到了基于 Postgres 的优化器。
最直接的方法是查看查询的 EXPLAIN 计划:
-
查询计划的末尾会标明使用的优化器。例如:
-
若由 GPORCA 生成,末尾显示:
Optimizer: GPORCA -
若由 Postgres 优化器生成,末尾显示:
Optimizer: Postgres-based planner
-
-
若查询计划中包含
Dynamic <any> Scan类型的节点(如动态断言、动态序列、动态索引扫描等),则说明该计划由 GPORCA 生成,Postgres 优化器不会生成这些节点。 -
对于分区表查询,GPORCA 的
EXPLAIN输出只显示被裁剪后的分区数量,而不会列出具体分区;Postgres 优化器则会列出被扫描的每个分区。
除了 EXPLAIN 输出,日志中也会记录所使用的优化器类型。如果查询因某些原因不被 GPORCA 支持,系统会自动回退,并在日志中以 NOTICE 等级输出相关信息,说明为何回退。
你还可以开启配置参数 optimizer_trace_fallback,让 GPORCA 回退时的详细原因在 psql 中直接显示。
将服务器配置参数 optimizer_trace_fallback 设置为 on,可在命令行中查看 GPORCA 回退的具体原因。
示例
以下示例演示了启用 GPORCA 时,对分区表执行查询的效果。
下面的 CREATE TABLE 语句创建了一个按日期进行范围分区的表:
CREATE TABLE sales (trans_id int, date date,
amount decimal(9,2), region text)
DISTRIBUTED BY (trans_id)
PARTITION BY RANGE (date)
(START (date '2016-01-01')
INCLUSIVE END (date '2017-01-01')
EXCLUSIVE EVERY (INTERVAL '1 month'),
DEFAULT PARTITION outlying_dates );
GPORCA 生成的计划只显示所选分区的数量,而不列出分区名称:
-> Partition Selector for sales (dynamic scan id: 1) (cost=10.00..100.00 rows=50 width=4)
Partitions selected: 13 (out of 13)
若某些分区表查询不被 GPORCA 支持,系统会自动切换为 Postgres 优化器。Postgres 生成的 EXPLAIN 会列出所有被访问的分区。如下所示:
-> Append (cost=0.00..0.00 rows=26 width=53)
-> Seq Scan on sales2_1_prt_7_2_prt_usa sales2 (cost=0.00..0.00 rows=1 width=53)
-> Seq Scan on sales2_1_prt_7_2_prt_asia sales2 (cost=0.00..0.00 rows=1 width=53)
...
下面的示例展示了查询回退到 Postgres 优化器时的日志输出:
执行以下查询:
EXPLAIN SELECT * FROM pg_class;
系统会使用 Postgres 优化器,并在日志中输出一条 NOTICE 消息,说明 GPORCA 未处理该查询的原因。
NFO: GPORCA failed to produce a plan, falling back to Postgres-based planner
DETAIL: Falling back to Postgres-based planner because GPORCA does not support the following feature: Non-default collation
