

GPORCA overview
GPORCA is an enhanced query optimizer built on top of the PostgreSQL planner, designed to improve query planning and optimization. It offers high scalability and delivers more efficient optimization, especially on multi-core architectures. Apache Cloudberry uses GPORCA by default to generate query execution plans when supported.
GPORCA significantly enhances query performance in the following areas:
- Queries on partitioned tables
- Queries with common table expressions (CTEs)
- Queries with subqueries
In Apache Cloudberry, GPORCA and the PostgreSQL-based planner coexist. By default, the system first attempts to use GPORCA. If GPORCA does not support a particular query, the system automatically falls back to the PostgreSQL optimizer.
The following diagram illustrates GPORCA's role in the overall query planning architecture:
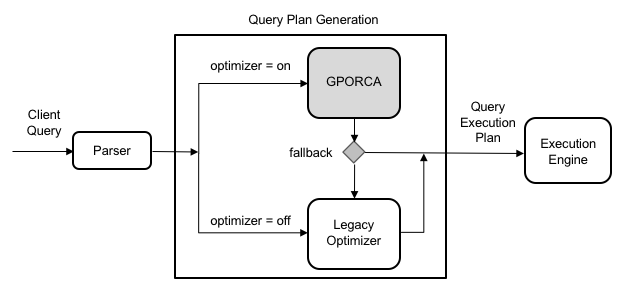
Note that all server parameters used to configure PostgreSQL planner behavior are ignored when GPORCA is enabled. These parameters only take effect if the system falls back to using the PostgreSQL optimizer.
Enable or disable GPORCA
You can enable or disable GPORCA using the optimizer server configuration parameter.
Although GPORCA is enabled by default, you can configure the optimizer parameter at the system, database, session, or query level to control whether GPORCA is used.
- The
optimizerparameter enables or disables GPORCA. - The
optimizer_controlparameter determines whether changes tooptimizerare allowed. Ifoptimizer_controlis set tooff, any attempt to modifyoptimizerwill result in an error. To allow changes, setoptimizer_controltoon.
Enable GPORCA system-wide
You can enable GPORCA across the entire system by setting the optimizer server parameter.
-
Log in to the primary node as the Apache Cloudberry administrator user
gpadmin. -
Run the following
gpconfigcommand to set the parameter toon:gpconfig -c optimizer -v on --coordinatoronly -
Reload the configuration to apply changes without restarting the system:
gpstop -u
Enable GPORCA for a database
You can enable GPORCA for a specific database using the ALTER DATABASE command. The following example enables GPORCA for the test_db database:
ALTER DATABASE test_db SET optimizer = on;
Enable GPORCA for a session or query
You can enable GPORCA in the current session using the SET command. For example, after connecting to Apache Cloudberry via psql, run:
SET optimizer = on;
To enable GPORCA for a single query only, run the above SET command just before executing the query.
Determine which query optimizer is used
When GPORCA is enabled (which is the default), you can determine whether Apache Cloudberry is using GPORCA or has fallen back to the PostgreSQL planner by inspecting the EXPLAIN output.
The most straightforward method is to look at the end of the query plan:
-
The optimizer used is indicated at the end of the plan. For example:
-
If the plan is generated by GPORCA, it shows:
Optimizer: GPORCA -
If the plan is generated by the PostgreSQL planner, it shows:
Optimizer: Postgres-based planner
-
-
If the plan includes nodes such as
Dynamic <any> Scan(e.g., Dynamic Assert, Dynamic Sequence, Dynamic Index Scan), it was generated by GPORCA. The PostgreSQL planner does not produce these node types. -
For partitioned table queries, GPORCA's
EXPLAINoutput only displays the number of pruned partitions, without listing them individually. In contrast, the PostgreSQL planner lists every scanned partition.
In addition to the EXPLAIN output, the optimizer type is also recorded in the logs. If GPORCA cannot support a query and falls back to the PostgreSQL planner, the system logs a NOTICE with an explanation.
You can also enable the optimizer_trace_fallback parameter to display detailed fallback reasons directly in psql.
Setting the server parameter optimizer_trace_fallback to on allows you to view detailed fallback reasons in the command-line interface when GPORCA falls back.
Example
The following example demonstrates the behavior of a query on a partitioned table when GPORCA is enabled.
The CREATE TABLE statement below creates a range-partitioned table based on the date column:
CREATE TABLE sales (trans_id int, date date,
amount decimal(9,2), region text)
DISTRIBUTED BY (trans_id)
PARTITION BY RANGE (date)
(START (date '2016-01-01')
INCLUSIVE END (date '2017-01-01')
EXCLUSIVE EVERY (INTERVAL '1 month'),
DEFAULT PARTITION outlying_dates );
The plan generated by GPORCA only shows the number of selected partitions, without listing their names:
-> Partition Selector for sales (dynamic scan id: 1) (cost=10.00..100.00 rows=50 width=4)
Partitions selected: 13 (out of 13)
If a particular partitioned table query is not supported by GPORCA, the system automatically falls back to the PostgreSQL optimizer. In such cases, the EXPLAIN output lists all accessed partitions. For example:
-> Append (cost=0.00..0.00 rows=26 width=53)
-> Seq Scan on sales2_1_prt_7_2_prt_usa sales2 (cost=0.00..0.00 rows=1 width=53)
-> Seq Scan on sales2_1_prt_7_2_prt_asia sales2 (cost=0.00..0.00 rows=1 width=53)
...
The following example shows the log output when a query falls back to the PostgreSQL optimizer:
Run the following query:
EXPLAIN SELECT * FROM pg_class;
The system uses the PostgreSQL planner and logs a NOTICE message indicating why GPORCA did not handle the query:
INFO: GPORCA failed to produce a plan, falling back to Postgres-based planner
DETAIL: Falling back to Postgres-based planner because GPORCA does not support the following feature: Non-default collation
